

オープンな日本語マルチモーダルモデルを開発
―142億パラメータを持つ日本語に特化した視覚言語モデル―
- プレスリリース
2025年2月25日
東京大学
発表のポイント
- 142億パラメータを持つオープンな日本語に特化したマルチモーダルモデルを開発しました。構築されたモデルは、出力の利用が制限されている大規模言語モデル(chatGPT-4o等)によって生成されたデータを用いないモデルとしては、最高のスコアを達成しました。
- 日本語マルチモーダルモデルの訓練には、大量の画像と日本語テキストのペアデータセットの構築が課題となりますが、本研究では、Webからクロールした画像などをもとに、英語マルチモーダルモデルや日本語言語モデルを用いて画像・日本語テキストデータセットを合成することで解決しました。
- 今回構築した日本語特化のマルチモーダルモデルは汎用的なものであるため、今後日本語を用いたマルチモーダルを扱う様々なAIモデルに役立つことが期待されます。また、今後は更なるモデルのスケールアップや日本語医療モデルへの展開を行っていきます。


概要
東京大学先端科学技術研究センターの上原助教と原田教授らによる研究グループは、142億パラメータを持つオープンな日本語に特化したマルチモーダルモデル(注1)を開発しました(図1)。
日本語マルチモーダルモデルの訓練には、大量の画像と日本語テキストのペアデータセットの構築が課題となりますが、本研究では、Webからクロールした画像などをもとに、英語マルチモーダルモデルや日本語言語モデルを用いて画像・日本語テキストデータセットを合成することで解決しました。合成されたデータには、生成物の利用が制限されるchatGPT-4o等のサービスを用いていないため、本モデルはオープンに利用可能です。また、開発したモデルは、利用制限のあるデータを用いていない既存モデルと比較して高い性能を持ち、この研究成果は今後日本語を用いたマルチモーダルを扱う様々なAIモデルに役立つことが期待されます。

発表内容
大規模言語モデル(LLM)(注2)の研究開発は世界的に急速な進歩を遂げ、テキストのみならず画像や音声など複数モダリティを扱う研究が活発化しています。特に、画像とテキストを同時に入力可能な大規模視覚言語モデル(VLM)(注3)は、複数の商用サービスにも導入され、その有用性が広く認識されつつあります。しかしながら、これらの商用VLMの多くはAPIを通じてのみ利用可能であり、モデルのパラメータや学習過程などの情報は一般に非公開です。学術コミュニティでは、よりオープンな形で研究が進められますが、大半は英語圏のデータに特化して学習された英語用モデルであり、日本語を主対象としたVLMはほとんど存在しません。日本語VLMを開発する上での最大の課題は、学習データの不足です。VLMの訓練には、画像とテキストのペアデータセットが必要になりますが、日本語のテキスト・画像ペアは既存の公開データセットを総合しても数百万件規模にとどまります。英語圏のVLMが数千万件規模のデータで訓練されていることを鑑みると、これは十分とはいえません。そこで、本研究では、Webからクロールした画像などをもとに、英語VLMや日本語LLMを用いて画像・日本語テキストデータセットを合成し、日本語VLMを学習しました。
構築されたモデル(図2)は、出力の利用が制限されているLLMによって生成されたデータを用いないモデルとしては、最高のスコアを達成しました。今回構築した日本語特化のマルチモーダルモデルは汎用的なものであるため、今後日本語を用いたマルチモーダルを扱う様々なAIモデルに役立つことが期待されます。また、今後は更なるモデルのスケールアップや日本語医療モデルへの展開を行っていきます。
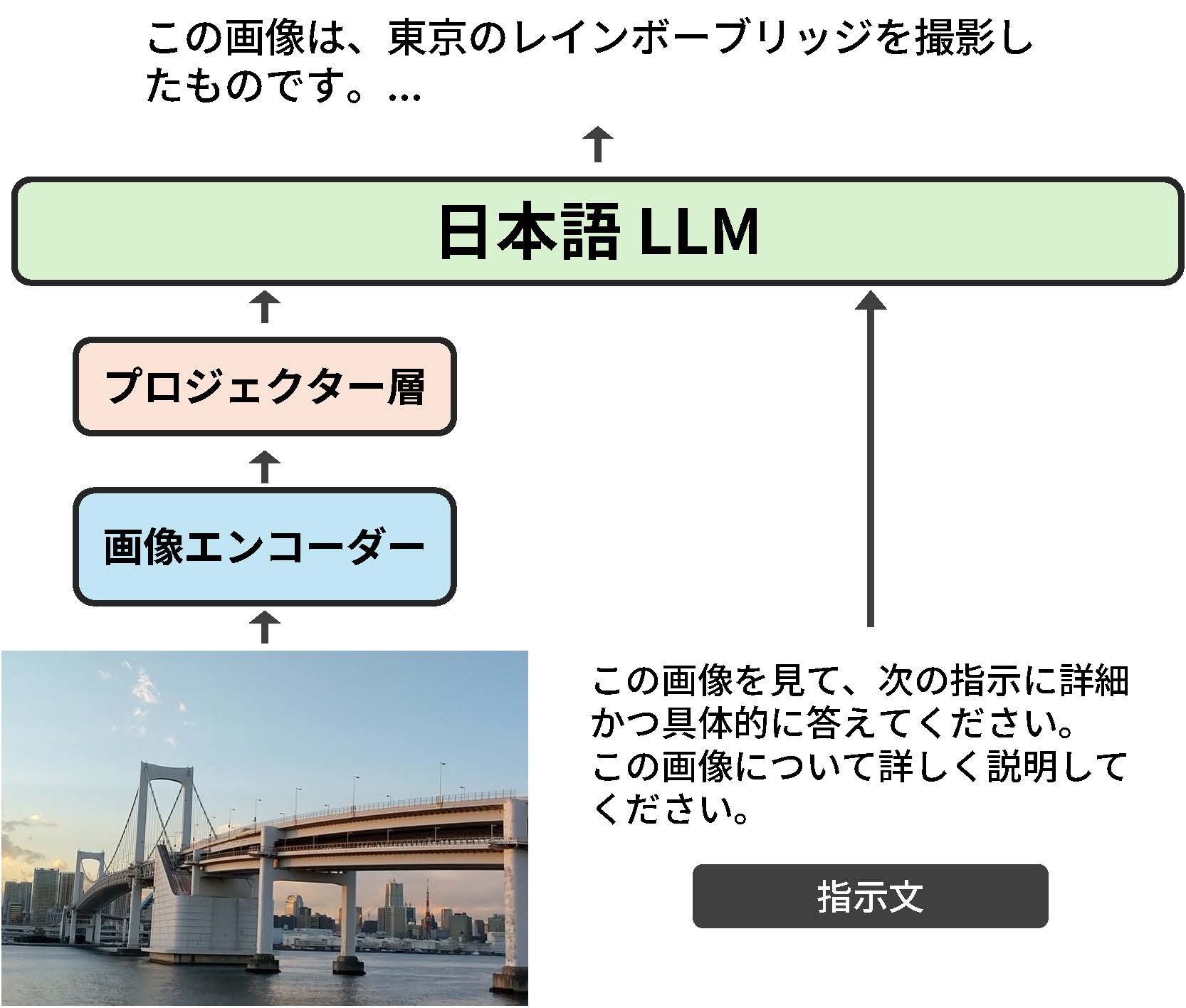
画像エンコーダ、日本語LLM、両者をつなげるプロジェクタ層から構成されています。
〇関連情報:言語処理学会 発表論文集(2025年3月3日更新予定):
https://www.anlp.jp/guide/nenji_proceedings.html
発表者・研究者等情報
東京大学
先端科学技術研究センター
原田 達也 教授
兼:国立情報学研究所 医療ビッグデータ研究センター 副センター長
兼:理化学研究所 革新知能統合研究センター チームリーダー
上原 康平 助教
兼:理化学研究所 革新知能統合研究センター 客員研究員
黒瀬 優介 特任講師
兼:理化学研究所 革新知能統合研究センター 客員研究員
大学院情報理工学系研究科
ガオ ファン(Gao Fan)博士課程
金澤 爽太郎 修士課程
坂本 拓彌 修士課程
大学院工学系研究科
チェン ジアリ(Chen Jiali)博士課程
竹田 悠哉 修士課程
ヤン ボーミン(Yang Boming)博士課程
チャオ シンジエ(Zhao Xinjie)修士課程
理化学研究所 革新知能統合研究センター
安道 健一郎 特別研究員
兼:東京大学 先端科学技術研究センター 客員研究員
国立情報学研究所
医療ビッグデータ研究センター
村尾 晃平 特任准教授
クラウド基盤研究開発センター
吉田 浩 特任教授
情報・システム研究機構
喜連川 優 機構長
兼:東京大学 特別教授室 特別教授
データサイエンス共同利用基盤施設
合田 憲人 教授
兼:国立情報学研究所 アーキテクチャ科学研究系 教授
田村 孝之 特任教授
学会情報
- 学会名:
- 言語処理学会第31回年次大会
- 題名:
- Asagi:合成データセットを活用した大規模日本語VLM
- 著者名:
- 上原康平、黒瀬優介、安道健一郎、ChenJiali、GaoFan、金澤爽太郎、坂本拓彌、竹田悠哉、Yang Boming、Zhao Xinjie、村尾晃平、吉田浩、田村孝之、合田憲人、喜連川優、※原田達也
研究助成
本研究は、戦略的イノベーション創造プログラム(SIP)「統合型ヘルスケアシステムの構築(課題番号:JPJ012425)」、JSTムーンショット型研究開発事業(課題番号:JPMJMS2011)、CREST(課題番号:JP-MJCR2015)、JSPS科研費(課題番号:JP23K16990、JP23K19971)、及び東京大学Beyond AI研究推進機構の基礎研究費(AI自体の進化)の支援を受けたものです。
用語解説
- (注1)マルチモーダルモデル
大規模マルチモーダルモデルは、テキストだけでなく画像・音声・動画など複数のデータ形式(モーダル)を統合的に理解・生成できるAIモデルで、画像認識や説明、映像を用いた対話などが可能です。 - (注2)大規模言語モデル
大規模言語モデル(LLM)は、大量のテキストデータを学習し、自然言語の理解や生成を行う人工知能(AI)モデルで、翻訳・要約・対話などに活用されます。 - (注3)大規模視覚言語モデル
視覚言語モデル(VLM)は、画像とテキストを組み合わせて理解・生成できるマルチモーダルモデルの一種で、画像キャプション生成や視覚質問応答(VQA)などに活用されます。
問合せ先
東京大学 先端科学技術研究センター
教授 原田 達也(はらだ たつや)
関連タグ
