

オープンな医療用マルチモーダルモデルを開発
―142億パラメータを持つ日本語に特化した医療用視覚言語モデル―
- プレスリリース
2026年3月6日
東京大学
理化学研究所
発表のポイント
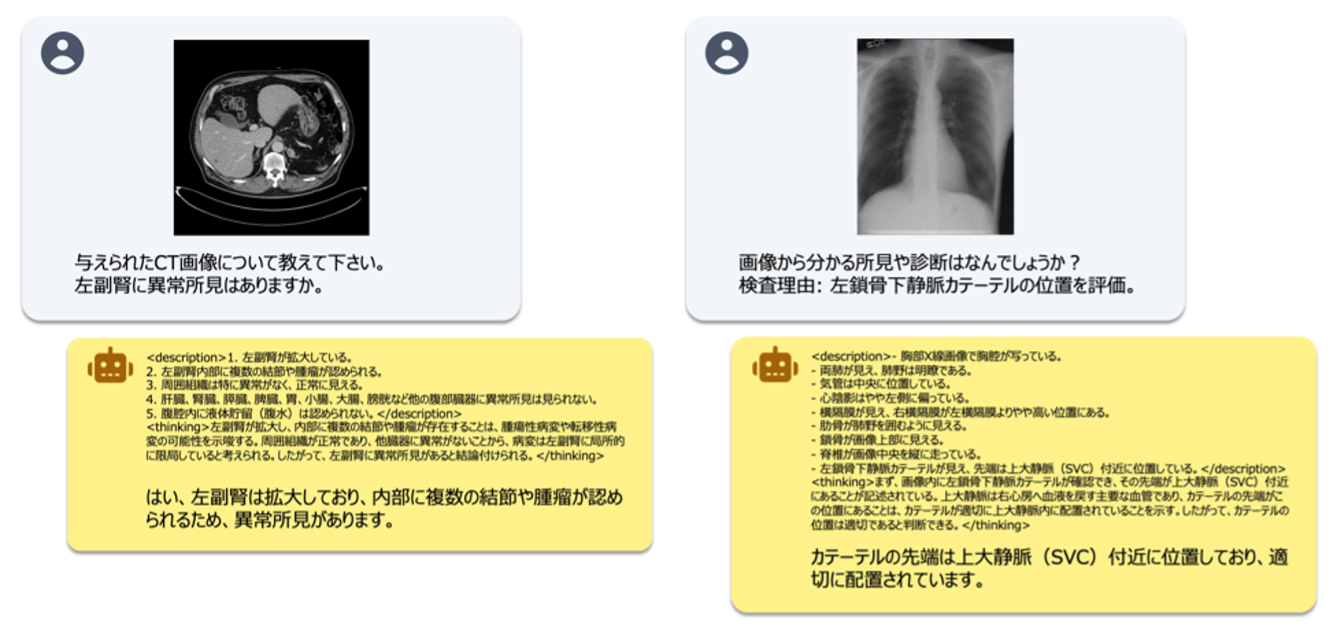
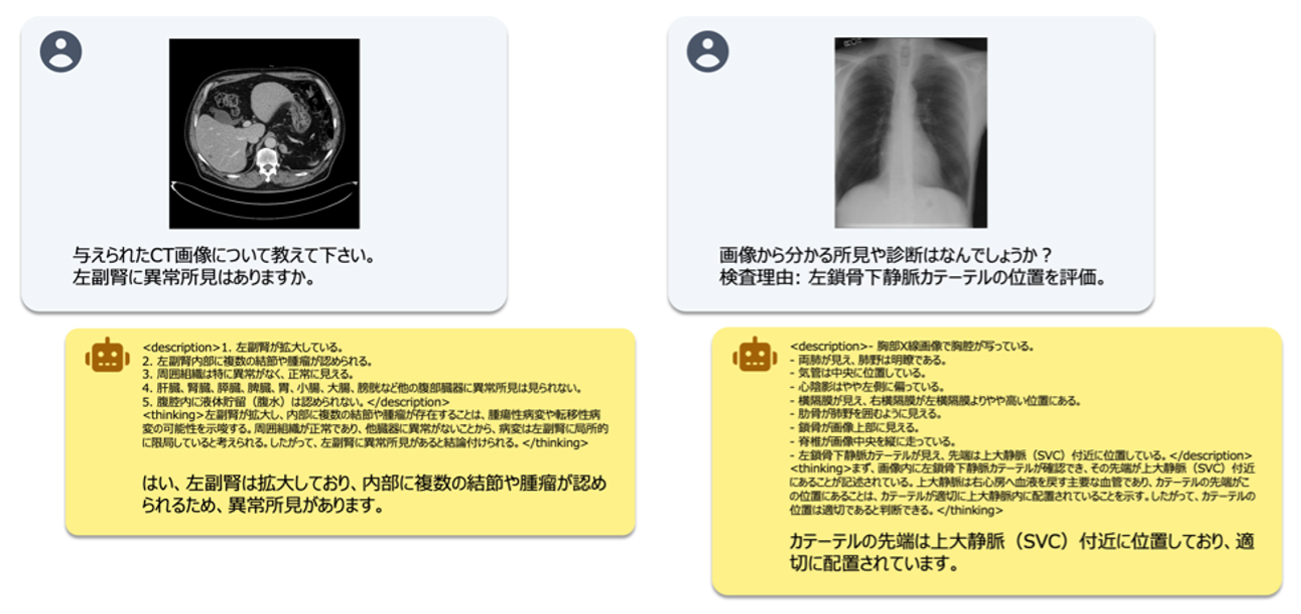
- 私たちは、142億パラメータを有する日本語に特化した医療用マルチモーダル(画像+テキスト)モデルを開発しました。本モデルは、出力の利用が制限される大規模言語モデル(例:ChatGPT等)によって生成されたデータを用いずに学習したモデルとして、公開ベンチマークにおいて最高水準の性能を達成しました。
- 日本語医療マルチモーダルモデルの学習には、大量の医療画像と日本語テキストのペアデータの整備が大きな課題となりますが、本研究では、最大の障壁である学習データ不足を補うため、英語データを加工・翻訳することで、約1,200万件の日本語医療学習データを作成しました。さらに性能向上のため、思考過程を段階的に記述する形式(Chain-of-Thought形式)のデータを導入し、推論の過程を明示的に出力できるモデルを構築しました。
- 本モデルは日本語医療領域で幅広く利用可能な汎用基盤モデルであり、今後、日本語を用いるさまざまな医療AI(診断支援,所見生成,医用画像理解など)の基盤として活用されることが期待されます。今後は、さらなるスケールアップに加え、診療科別の専門モデルへの展開も進めていきます。
概要
東京大学先端科学技術研究センター/理化学研究所革新知能統合研究センターの安道健一郎特別研究員、黒瀬優介特任講師、原田達也教授らによる研究グループは、142億パラメータを持つオープンな日本語に特化した医療用マルチモーダルモデル(注1)を開発しました。
日本語医療マルチモーダルモデルの訓練には、大量の医療画像と日本語テキストのペアデータセットの構築が課題となります。本研究では、モデル構築における最大の障壁である訓練データ不足を補うため、英語データを加工して約1,200万件の日本語医療学習データを作成しました。さらに、性能向上のために思考連鎖形式のデータを導入し、推論過程を明示的に出力できるモデルを構築しました。
また、本研究で作成した合成データは、生成物の利用が制限されるChatGPT等の大規模言語モデル(注2)を用いていないため、本モデルはオープンに利用可能です。開発したモデルは、利用制限のあるデータを用いない既存モデルと比較して高い性能を示しており、本研究成果は今後、日本語を用いたマルチモーダル医療AIモデルの基盤として幅広く活用されることが期待されます。
発表内容
近年、画像と言語を統合的に扱う大規模視覚言語モデル(注3)(VLM)は、ChatGPTやGeminiといった商用モデルを筆頭に急速な発展を遂げています。我々の研究チームはこれまで、日本語VLM開発における最大の障壁が学習データの不足にあることを指摘し、合成データの活用によって高性能な汎用日本語VLMを構築してきました。また、将来的な展開として、より高度な専門性が求められる医療ドメインへの適用を掲げてきました。
医療分野における生成モデルの活用については、公的ガイドラインの改定により環境整備が進みつつあります。一方で、国内の医療情報は厳重に保護されており、多くの医療機関では組織外への情報持ち出しが制限されています。そのため、クラウドAPIへの依存を避け、クローズドな環境で運用可能な「オンプレミス前提のオープンな医療特化モデル」への需要は極めて高いのが現状です。既にテキスト領域では日本語医療LLMの開発が進んでいるものの、画像を含むVLMにおいては、医療に特化したオープンな日本語モデルは依然として存在していませんでした。
そこで本研究では、これらの課題を解決するため、医療分野に特化したオープンな日本語VLMを新たに開発しました。大規模な医療VLMの開発において最大のボトルネックとなる画像テキスト対データの不足に対しては、英語の医療データを活用し、約1,200万件の日本語学習データを構築することで対処しました。本データ規模は、先行研究で課題としていた数百万件規模の制約を大きく上回ります。さらに性能向上のため、Chain of Thought(CoT)を模した深い推論過程を出力させる学習手法を導入しました。本モデルならびに訓練データの全件、評価データの一部は、国内の医療AI研究の発展に寄与すべく、公開を予定しています。
発表者・研究者等情報
東京大学
先端科学技術研究センター
原田 達也 教授
兼:理化学研究所 革新知能統合研究センター チームディレクター
兼:国立情報学研究所 医療ビッグデータ研究センター 副センター長
黒瀬 優介 特任講師
兼:理化学研究所 革新知能統合研究センター 客員研究員
生産技術研究所
合田 和生 教授
医学部附属病院
小寺 聡 特任講師
理化学研究所
革新知能統合研究センター
安道 健一郎 特別研究員
兼:東京大学 先端科学技術研究センター 客員研究員
自治医科大学
データサイエンスセンター
牧元 久樹 准教授
菊地 智博 講師
国立がん研究センター研究所
医療AI研究開発分野
小林 和馬 主任研究員
国立情報学研究所
医療ビッグデータ研究センター
村尾 晃平 特任准教授
クラウド基盤研究開発センター
吉田 浩 特任教授
情報・システム研究機構
喜連川 優 機構長
兼:東京大学 特別教授室 特別教授
データサイエンス共同利用基盤施設
合田 憲人 教授
兼:国立情報学研究所 アーキテクチャ科学研究系 教授
田村 孝之 特任教授
論文情報
- 雑誌名:
- 言語処理学会第32回年次大会 発表論文集(発表予定:2026年3月9日~13日)
- 題名:
- 医療用大規模日本語視覚言語モデルの構築
- 著者名:
- 安道健一郎,黒瀬優介,菊地智博,牧元久樹,小寺聡,小林和馬,合田和生,村尾晃平,吉田浩,田村孝之,合田憲人,喜連川優,原田達也
- URL:
- https://www.anlp.jp/guide/nenji_proceedings.html
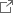
研究助成
本研究は,戦略的イノベーション創造プログラム(SIP)「統合型ヘルスケアシステムの構築」JPJ012425,JSTムーンショット型研究開発事業JPMJMS2011,CREST課題番号JP-MJCR2015,JSPS科研費JP23K16990,及び東京大学Beyond AI研究推進機構の基礎研究費(AI自体の進化)の支援を受けたものです.
用語解説
- (注1)マルチモーダルモデル
大規模マルチモーダルモデルは、テキストだけでなく画像・音声・動画など複数のデータ形式(モーダル)を統合的に理解・生成できるAIモデルで、画像認識や説明、映像を用いた対話などが可能です。 - (注2)大規模言語モデル
大規模言語モデル(LLM)は、大量のテキストデータを学習し、自然言語の理解や生成を行う人工知能(AI)モデルで、翻訳・要約・対話などに活用されます。 - (注3)視覚言語モデル
視覚言語モデル(VLM)は、画像とテキストを組み合わせて理解・生成できるマルチモーダルモデルの一種で、画像キャプション生成や視覚質問応答(VQA)などに活用されます。 - (注4)LLM as a Judge
LLM as a Judgeとは、人間(の代わり)にGeminiなどの高性能なLLMを使って、他のAIモデルが生成した回答の質を評価・採点させる手法です。
問合せ先
東京大学先端科学技術研究センター
教授 原田 達也(はらだ たつや)
関連タグ
