

- ホーム
- 研究について
- 研究者紹介 フロントランナー
- 012:原田 達也 教授
012:原田 達也 教授
原田 達也 教授

原田 達也 教授
マシンインテリジェンス 分野
公開日:2020年12月22日
“機械独自の知能”は可能か――
人間の知能に限定しない、機械ならではの知能の実現に挑む
膨大なデータが容易に入手できるようになる一方で、コンピューティングパワーも飛躍的に向上している。こうした状況を背景に、機械学習やAI(人工知能)は飛躍的な進化を遂げている。
原田達也教授は、マシンインテリジェンス分野の研究に、独自のアプローチで取り組んでいる。発想の起点となるのは、「何を知能のモデルとするか」だ。いまAI技術の開発は、さまざまな方向性で進められており、人間の脳の構造をモデルにしたものもある。だが原田教授は、人間にモデルを限定することなく、機械にとってのベストな知能を追究している。
新聞記者のようなロボットをつくる
原田研究室の原点は、約15年前にスタートした「ジャーナリストロボット」プロジェクトにある。
「2006年、教員として初めて指導を担当した学生からのリクエストが、“新聞記者のようなロボットをつくりたい”でした。当時の技術レベルから考えれば、途方もない夢のような話であり、常識的に判断すれば不可能に決まっている。ということは、万が一実現すればとんでもなくすごいことになる、と思ったのです」
新聞記者のようなロボットとは、どのようなものだろうか。人間をモデルとするならば、次のような機能が求められるだろう。
まず取材に行くために、周囲の環境を認識したうえで、自力で自由自在に動き回る機動性が必要だ。続いて取材相手にインタビューする、すなわち質問をして相手の答えを理解し、必要ならば質問を重ねる能力も欠かせない。そのうえで、取材時の一連の会話情報をデータとして記録し、その内容をサマライズし文章化までできてはじめて一応の完成形となる。このようなロボットは、2020年時点で考えられる限りのAI技術をすべて詰め込んだとしても、ようやく成立するかどうかといったレベルである。
「もちろん夢物語のような話ですが、一つずつ課題をクリアしていけば、いつかは到達できるのではないかと考えたのです。そこで最初に手をつけたのが、環境を認識する『コンピュータビジョン』の開発です。これに求められるのは、画像を通して現実世界の情報を正しく認識し、状況を理解する能力です。このシステムを実装したのが『人工知能ゴーグル』です」

世界を認識するゴーグルの開発
「人工知能ゴーグル」は、小型カメラと液晶ヘッドマウントディスプレイを備えたゴーグル、腰につける小型のタブレット型コンピュータで構成されるコンパクトなシステムである。最初にゴーグルのカメラを通して、現在の環境、例えば部屋全体の様子を取り込み、映っている画像とその名前をコンピュータに学習させる。その後、人がゴーグルを装着し、学習済みの部屋の中を見ると、映っているモノの名前が正しくディスプレイに表示される。画像認識能力を備えたロボットの実現に一歩近づくシステムである。
「2008年の段階で、こうした画像処理を、当時一般的だった手法で実現するには、膨大な計算リソースが必要でした。けれども私たちは、独自開発した高速高性能の画像認識検索アルゴリズムを駆使して、小さなコンピュータ1台だけで、リアルタイムな画像認識と検索を可能にしました」
画期的な画像認識システムとはいえ、ジャーナリストロボットの実現には、まだまったく力不足であることは明らかだった。なぜなら部屋の中にある物体の数は有限で、事前にすべてを学習できる。だが、学習済みの部屋の外に一歩出れば、認識すべき対象は爆発的に増える。無限ともいえる現実世界の対象物をどうやって学習させるのか。

課題解決のため、原田教授が次に取り組んだのが、Webデータを活用する学習法の開発だ。もちろんこのとき、すなわち2008年の時点では、まだ「ビッグデータ」なる用語は一般的ではなかった。現在の機械学習では、膨大なWebデータを参照した学習はごく当たり前の手法となっている。けれどもそうした手法がまだ普及していなかった当時でも、アルゴリズムを工夫し参照できるデータ量を増やした結果、画像認識の精度を大幅に向上できた。その結果、原田教授らの研究チームは、2012年の画像認識やAIに関する国際コンペティション『ILSVRC(ImageNet Large Scale Visual Recognition Challenge)』で見事に入賞を果たす。
「我々は、大規模画像認識コンペティションのタスク1(識別部門)で2位、タスク3(詳細物体認識部門)で1位となりました。しかし、このコンペで話題をさらったのは、カナダ・トロント大学のヒントン教授が率いるSuper Visionチームでした。ヒントン教授のチームは、タスク1とタスク2(物体検出部門)において、大規模なデータセットにディープニューラルネットワーク(DNN)を適用し、低いエラー率をはじめ、驚異的な数値を叩き出せることを世界で初めて示しました。これが、深層学習(ディープラーニング)ブームの幕開けとなりました。DNNを活用すれば、従来のコンピュータビジョンとは次元の異なる成果を出せる。圧倒的な成果を出したDNNに世界中の研究者が注目し、今のAIブームに繋がっていきました」

“開かれた世界”で、機械はいかに振る舞うか
2012年にはILSVRCの前に、Googleのアンドリュー・ン(Andrew Ng)らのチームが、深層学習を用いた画像認識技術を開発し話題となっていた。AIに、YouTubeから抽出した1000万枚の画像を学習させると、AIが猫を見分けられるようになったのだ。これもDNNを活用していたが、DNNが本当に使えると世界が認識を新たにしたのは、ILSVRCにおけるヒントン教授の成果が直接のきっかけである。
ただ、コンピュータパワーが指数関数的に高まりつつあった当時の状況を踏まえると、こうした現象は当然の結果に過ぎないと、原田教授は指摘する。
「領域が限定され認識する対象が定められていて、その領域内で大量にデータが得られる。このような条件を充たす、いわば箱庭的な条件のもとでは、人間よりもコンピュータの方が賢くなるのが当たり前です。コンピュータが人間を凌駕する現象は、既に将棋や囲碁の世界で現実のものとなっています。囲碁では打ち手の組み合わせの数が膨大な数に上ると言われますが、所詮は有限の世界。有限なら、コンピュータが進化すれば、いずれ人間を凌駕するのは目に見えています」
そのとき考えるべきは、機械と人間の根源的な違いだと原田教授は強調する。閉じた箱庭ではなく、“開かれた”現実の世界において、つまりこれまで学習した経験のない環境に置かれると、機械(AI)は状況を認識できない。対して人間なら、自分が未経験の状況に置かれていることを自覚し、誰かに質問したり自分で調べたりして理解できるようになる。この自発的学習能力が、機械と人間との決定的な違いなのである。
「こうした“無知の知”を、機械は持つことができません。つまり、『自分が何を分かっていないのか』が分からないし、そうした状況を言語化することもできない。人間でも適切な質問をできる人は賢い人です。分からないことがあれば、適切な答えが返ってくるような質問を作り出す。自発的な質問能力を機械に持たせるのは、極めて難易度の高い課題です。それを突き詰めれば、おのずと自然言語と実世界認識の融合研究といった領域に入っていくと思います」
まさしく、「ジャーナリストロボット」を研究の原点とする、原田教授ならではの問題意識とその展開である。

ロボットと人間、その知性の違い
「ジャーナリストロボット」には、優れたインタビュー能力が求められる。インタビューに際しては、自分が知らない何かについて疑問をいだき、それを言語化する能力が必要だ。この課題は容易にはクリアできないと原田教授は語る。
「そこでいったん考え方を変えてみる手もあります。もちろん言語化能力は重要ですが、必ずしも人間の言語活動を見本とする必要はありません。人間の言語能力は、あくまでも人間とやり取りする場合に必要な能力です。人間を介さずに、コンピュータ同士だけでやり取りするのであれば、人間の言語は必要ありません」
この、“コンピュータ独自の能力”という発想を、視覚について当てはめるとどうなるだろうか。例えば、赤外線を使った画像認識システムを導入すれば、人間の目では認識できないような状況をも正確に把握できるはずだ。
「人間はたしかに賢い。だから参考にすべき点、真似るべき要素は大量にあります。しかし、人間のような知性を機械の知性のゴールにしなければならない理由はどこにもありません。画像認識を例にすれば、対象物に向けてレーザーを放射し、反射光を解析すれば、その化学組成まで分析できてしまいます。これは人間には不可能な芸当です。思考パターンや言語化能力についても同じように、機械ならではのものを編み出せるのではないかと考えています」
当たり前の話だが、人間と機械は違う。従って、必ずしも人間をモデルにして機械を考える必要はない。一方で、人間から学ぶべき点も、もちろん多くある。原田教授が目指すのは、人間と機械の違いを踏まえたうえで、機械にとってのベストな知能をフラットに追究することだ。
データがなくとも、リソースがなくとも勝ち目はある
「人工知能ゴーグル」では、画像認識の精度を高めるため、適切な教師データを必要とした。教師データは、その数が多ければ多いほど、画像認識の精度が高まる。現在のAIシステムの基本的な考え方も同じだ。大量の教師データを集め(すなわちビッグデータだ)、それらを学習させたうえで予測システムに当てはめている。しかし、このシステムが万能なわけではない。
「分かりやすいのが医療の世界でしょう。世界全体で患者が100人程度の希少疾患を対象に、AIをどのように活用することができるのか。教師データ数の上限は、100と決まっているわけです。ではデータが少ないから、診断や今後の予測にAIは活用できないのか。この課題を解決するために取り組んでいるのが『Beyond AI』の取り組みです」
『Beyond AI』とは、東京大学とソフトバンク社らが産学共同で進めている世界最高レベルのAI実現に向けた取り組みである。2019年12月に『Beyond AI研究所』の設立を発表し、2020年8月に名称を『Beyond AI研究推進機構』に変更するとともに、共同研究を本格始動させた。
この共同研究では、AI自体のさらなる進化や、AIと異分野との融合など、最先端のAIを追求してさまざまな研究が行なわれている。そのなかで原田教授は、AI自体をさらに進化させるべく、「少ない教師データからの高精度予測モデル自動構築」をテーマにした研究に取り組んでいる。文字通り、限られた教師データから、精度の高い推論結果を導き出すAIの開発を目指している。
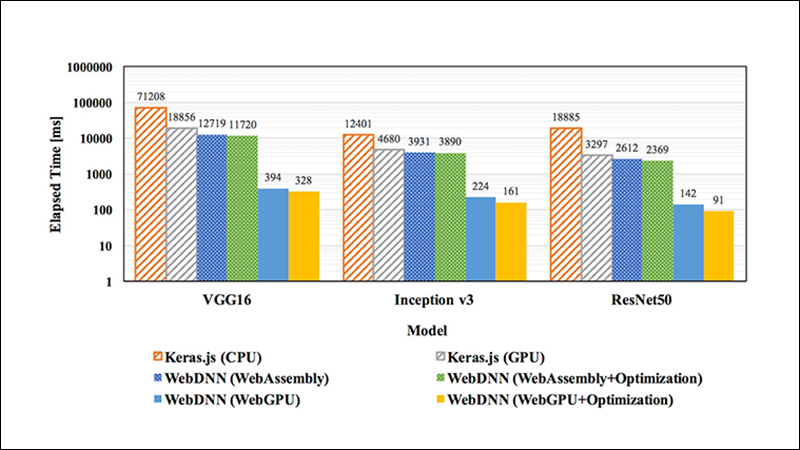
もうひとつ、原田教授独特のアプローチの研究事例を紹介したい。いま主流のAI研究が目指すのは、大量の教師データをもとに、膨大なコンピュータリソースを使って、精度よく正解を導き出すことと言える。大量の教師データがなくとも、高精度の予測を可能にする研究が『Beyond AI』なら、集中的に管理された膨大なコンピュータリソースを使わずとも、高精度のAI実現を目指すのが、『WebDNN』の研究である。
「膨大なコンピュータリソースを使ってAIに予測をさせるというのは、たしかに王道のアプローチです。しかし、コンピュータリソースの多寡で勝負するのであれば、莫大なコンピュータリソースを持つ巨大なプラットフォーマーのGAFA(Google、Amazon、Facebook、Apple)が圧倒的に優位です。では、GAFA以外は何をしなくてもよいのか? そんなことはありません。別のアプローチを試せばよいのです」
原田教授が目をつけたのが、個人が所有するスマートフォンやパソコンだ。
「今のスマートフォンやパソコンは、20年前のスーパーコンピュータ並みの計算処理能力を持っています。しかも、それを持つ所有者が、四六時中スマホやパソコンを使っているわけではありません。その空きリソースを活用して計算させればいい。つまり、エッジ(周辺)にあるコンピュータリソースを使って学習させ、その結果を統合してスマートな知性を構築すればよいのです。スマホやパソコンには、特別なソフトをインストールする必要もない。そういうコンセプトで開発しているのが、『WebDNN』です。一箇所に集約したコンピュータリソースを使うのではなく、周辺のコンピュータでデータを集めることは、開かれた現実世界を認識するためにも必要になってきます。実現すれば、今のところ誰も考えていない知的なシステムになると考えています」
https://www.mi.t.u-tokyo.ac.jp/research/webdnn/
“機械知能”は、どのような夢を見るのか
「ジャーナリストロボット」からスタートした原田教授の関心は、さまざまな方向に広がっている。では、最終的にめざすゴールはどこにあるのだろうか。
「一つ明らかなのは、機械には機械にとって最適なシステムがあるはずだということです。今のAI研究は、人間の脳の構造をモデルとしたアプローチが主戦場です。この領域では、すでに数多くの研究者がしのぎを削っています。私もそこをフィールドに戦う必要はないのではないか。自分がいなければ研究が進まないような領域で、勝負をしたいと考えています」
そもそも人間の知性が最適解とは限らない、というのが原田教授の考え方だ。人間とて、進化の途上の生物の一種でしかない。したがって、人間を目標とするのではなく、機械ならではの理想的な知能を突き詰める。そんな意味を込めて定めた分野名称が、『マシンインテリジェンス=機械知能』だ。その究極の姿は、人間の知性とはまったくかけ離れたものとなるのだろう。
「人間には想像もできない夢を見ることができる」
原田教授がめざす究極の“機械知能”は、もしかすると「無知の知」を理解し、モチベーションすら持つロボットになるのかもしれない。


2001年東京大学大学院工学系研究科博士課程修了、博士(工学)。2001年、カーネギーメロン大学客員研究員、東京大学大学院情報理工学系研究科助手、2006年、東京大学大学院情報理工学系講師、2009年、同准教授を経て、2013年より同教授。理化学研究所確信知能統合研究センターチームリーダ、国立情報学研究所医療ビッグデータ研究センター客員教授を兼任し、2019年9月より現職。
関連タグ
